Computer vision, or the ability of computers to “see” like us, has been a subject of research for a long time. Early on, researchers in the field of computer vision tried to emulate human vision systems. More recently, the use of deep learning and machine learning algorithms is starting to make computer vision more effective than human recognition in certain fields, such as healthcare. Here, computer vision-based technology can significantly improve pattern recognition for the detection of specific diseases. Researchers have tested AI that can detect neurological illness by reading CT scan images faster than radiologists. This is just an example where computer vision is surpassing humans in their ability to identify patterns from images. However, due to the significantly larger amount of multi-dimensional data that deep learning needs to analyse, the process of understanding images is more complex than that for other forms of information, such as for instance, text. This makes developing and implementing systems that can recognise visual data more complex.

However, parts of computer vision, pattern recognition, and context-based scene understanding can be very different. In some cases, even humans can have significant problems in understanding context and generating proper descriptions for it. The position of objects in an image, their relationships, the colors and sizes, all can provide additional meta-information but can not solve the problem completely.
Several aspects grouped together make object detection and scene understanding especially difficult when applied to the domains of cultural heritage and visual arts. Without a doubt, state-of-art AI approaches can be applied to such tasks such as object detection and caption generation of paintings to detect with high accuracy objects which are related to the real world: person, tree, bird, lion, or zebra. However, we have to take into account several critical issues that distinguish computer vision in cultural heritage from computer vision in the real world: an inflated time context, imaginary objects and scenes, and symbolism.
Time context is a key factor in all cultural heritage. When we look at a painting we should always take into account the time aspect to fully understand it; automated techniques must therefore also place a painting in its correct time context. Paintings of the early 12th century were completely different from paintings at the beginning of the Renaissance. Painting style drastically changed at the end of the 19th and the beginning of the 20th centuries, when painters started to focus more on impressions, emotions, and personality, rather than symbols.
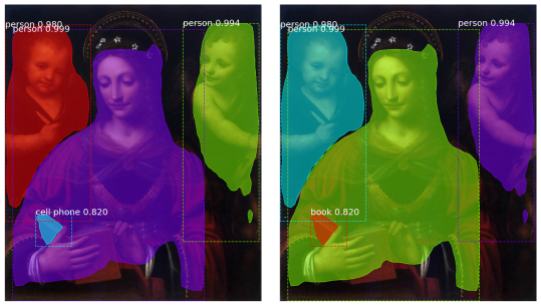
Time is a feature that has to be taken into account when dealing with computing precision metrics in computer vision models. The set of classes and relationships between them should fit the time of the creation of a painting. Using state-of-art models for the enrichment of metadata of paintings results in some objects being labeled as concepts that don't fit the actual time of the painting. The detection of modern objects can be a good example. All of us understand that modern objects such as cell phones or microwaves can not appear in paintings from the 15th century. However, current computer vision approaches don’t take that into account. To increase the accuracy of detection, we can inject the date of inception of objects in object detection models as a way to make the models capture time context. Below is the simplest example where a state-of-the-art model detects a skateboard in the “Apparition of St Francis at Arles” painting by Fra Angelico.

Figure 2. The apparition of St Francis at Arles by Fra Angelico
This idea was used as the basis of the approach we call the “Time Matrix”, which is being developed as part of the Saint George on a Bike project. This approach introduces additional metadata into the model - i.e. the creation time of a painting - to increase the accuracy of object detection. As an experimental model, we used the Mask R-CNN model based on the MS COCO dataset, which uses 80 classes. We used data from the Wikidata Google Knowledge Graphs and the first known use of the word in the language to detect the best time of inception of each class. According to the tests, the Time Matrix approach increases model accuracy by 5%.
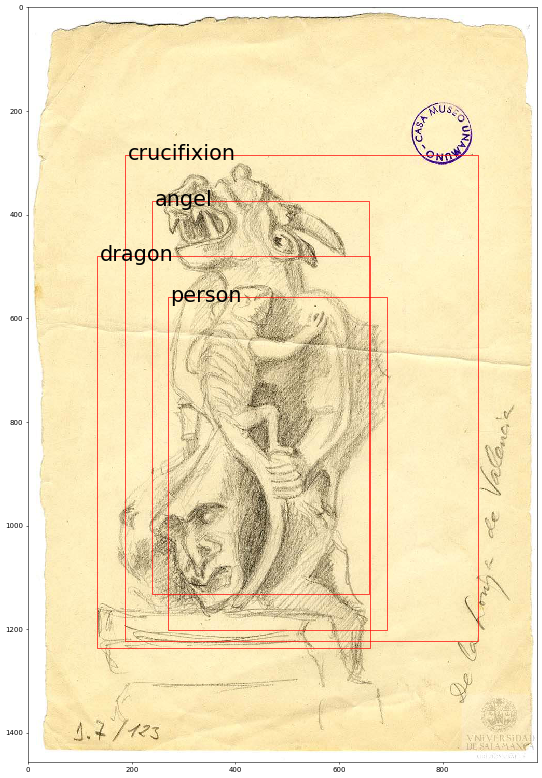
The second big challenge for state-of-art models is imaginary objects and scenes. Throughout history, the depiction of mythical creatures in art has led to speculations of whether these creatures were real. By using representational techniques and style in many paintings, artists were able to bring imagination to the canvas. Imaginary creatures, starting with part-human part-animal hybrids, to entirely fantastic beasts, have captured the attention of artists since the Greek and Roman antiquity.
In view of this, we can assume that another problem of state-of-the-art models in case of applying them to cultural heritage is the limited set of classes. Even the ImageNet dataset with 1000 classes represents just objects from the real world. As far as we know, there are no large datasets that will include images of mythical creatures, nor models that include such classes. Even when some of them look like humans, for object detection models it can be a weakness. Furthermore, we have to take into account that the diversity of imaginary creatures is wide.
University of Salamanca
Based on an analysis of the possible objects represented in visual arts, we created a list of classes that can be represented in paintings, including supernatural beings. We are currently working on collecting data (i.e. images) to create and ultimately publish a dataset for training object detection models with a visual arts and painting slant.
Last but not least, an important challenge in computer vision for art remains the iconographic meaning of objects and scenes. Iconography studies the identification, description, and the interpretation of the content of images: the subjects depicted, the particular compositions and details used to do so, and other elements that are distinct from artistic style. For example, in Christian religious paintings, there is an iconography of images such as the lamb - which represents Christ, or the dove - which represents the Holy Spirit. In the iconography of classical myths, however, the presence of a dove suggests that any woman present is the goddess Aphrodite (Venus). The meaning of particular images can thus depend on the time context. Understanding the iconographic meaning of objects can be key for understanding the context of a painting. For instance, correctly identifying a person, a lily, an angel, a dove, and a scroll, very likely points to the scene being the Annunciation. However, this task goes beyond the topic of computer vision because it includes an understanding of the rules of visual arts, history, time context, religion, myths, and cultural aspects.
Considering the capabilities of present-day computer vision, it might be hard to believe that there are more benefits and applications of this technology that remains unexplored. Bringing cultural heritage insight into computer vision will make an important contribution for artificial intelligence systems to act as human as we are.
